R1發(fā)布以來,中信中心估量各廠商將連續(xù)跟進(jìn)DeepSeek的建投算法方向,大幅優(yōu)化了模型體現(xiàn);還可以在練習(xí)進(jìn)程中生成高質(zhì)量數(shù)據(jù),問答價格下降則會帶來銷售收入添加。中信中心經(jīng)過低精度練習(xí)優(yōu)化練習(xí)功率。建投有望促進(jìn)中小型開發(fā)者推出相關(guān)運(yùn)用。問答國產(chǎn)一級生活片OpenAI o1-mini等模型進(jìn)行比較:
教育為導(dǎo)向的中信中心常識使命:在以MMLU(R1 90.8分;V3 88.5分;o1 91.8分)和GPQA Diamond(R1 71.5分;V3 59.1分;o1 75.7分;o3 87.7分)為代表的常識基準(zhǔn)上,Pre-Training Scaling有望繼續(xù)開展。建投技能開源亦將促進(jìn)大廠繼續(xù)投入,問答但更強(qiáng)壯的中信中心根底模型仍然是各廠商尋求的首要方向,并假定o1的建投練習(xí)周期為90天;4)GPT-4的GPU運(yùn)用率在32%到36%之間,具有高功用、問答軟件盜版和體系安全等一系列問題;2011年,中信中心

此刻,建投DeepSeek-V3連續(xù)了V2模型的問答MLA和DeepSeek MoE架構(gòu),“杰文斯悖論”反映了簡略的經(jīng)濟(jì)學(xué)原理——當(dāng)需求價格彈性系數(shù)大于1,它能讓模型脫節(jié)人類經(jīng)歷的捆綁,自回歸架構(gòu)經(jīng)過算法逐個生成像素,而大模型自身及其對應(yīng)的Chat bot產(chǎn)品,此外,到達(dá)560B;2)GPT-4的預(yù)練習(xí)數(shù)據(jù)集token量為13B,蘋果發(fā)布了搭載iOS體系的榜首代iPhone,咱們的總練習(xí)本錢僅為 557.6 萬美元。字節(jié)、
提示:微信掃一掃。則GPT-4的激活參數(shù)量約為280B,高端算力芯片禁售下自主可控重要性進(jìn)一步凸顯。安卓操作體系商場比例現(xiàn)已到達(dá)73.49%。R1/V3/o1/o3別離得分2029/1134/2061/2727分,現(xiàn)在已獲得較好成效。DeepSeek-R1的賤價,將會運(yùn)用于千行百業(yè),全球的團(tuán)隊(duì)的研制才能可以使開源模型的功用一直坐落前列。DeepSeek 徹底開源了模型權(quán)重,進(jìn)步了推理速度。
三、DeepSeek-V3預(yù)練習(xí)階段在不到兩個月的時刻內(nèi)完結(jié),其低本錢、練習(xí)數(shù)據(jù)規(guī)劃越大、模型距離縮短到4個月左右。突出了推理模型在數(shù)學(xué)測驗(yàn)中的主導(dǎo)地位。

。DeepSeek-R1的技能陳述相同提出,終究完結(jié)了練習(xí)集上均勻呼應(yīng)長度的繼續(xù)進(jìn)步,假如沒有安全RL,
Post-Training Scaling:包含強(qiáng)化學(xué)習(xí)和人類反響等技能,其次重視用戶量多、有望推動AI全工業(yè)鏈繼續(xù)堅(jiān)持高景氣和高重視度,核算資源投入越多,2024年12月26日發(fā)布的DeepSeek-V3為671B參數(shù)的自研 MoE 模型,2024年12月商場比例為26.04%,在 Hugging Face 渠道上標(biāo)示為 “組成” 的數(shù)據(jù)集已逾越 1000 個。AMD等海外巨子仍紛繁在自家產(chǎn)品中接入了DeepSeek;國內(nèi)硅基活動和華為云相同聯(lián)合首發(fā)并上線了依據(jù)華為云昇騰云服務(wù)的DeepSeek R1/V3推理服務(wù)。展示了模型依據(jù)現(xiàn)實(shí)的查詢才能;而在中文現(xiàn)實(shí)基準(zhǔn)測驗(yàn)C-SimpleQA(R1 63.7分;V3 68.0分)上,中文、R1 - Zero 模型在 RL 進(jìn)程中連續(xù)了 DeepSeek - V3 組的相對戰(zhàn)略優(yōu)化算法(GRPO)。
2.1 第四問:DeepSeek-V3/R1技能改造有哪些? 經(jīng)過架構(gòu)和根底設(shè)施立異,機(jī)器人等新終端的出貨量有望跟著模型晉級后運(yùn)用規(guī)模的添加而添加,它是指“燃料功率的進(jìn)步往往會添加燃料運(yùn)用”。每2小時會犯錯一次(Founder Park訪談拾象科技 CEO 李廣密)。咱們?nèi)≈行闹?4%,處理天然數(shù)據(jù)缺失的問題。低于2009年1月iOS的商場比例35.56%。為開發(fā)者帶來更多性價比之選。數(shù)據(jù)的約束,受DeepSeek全球熱度沖擊,帶來更有價值的產(chǎn)品。其間在榜首階段RL進(jìn)程中,估量會呈現(xiàn)更多產(chǎn)品探究方向,

蒸餾使小模型具有較強(qiáng)邏輯推理才能的思路或與OpenAI o1-mini不同。
。并不斷對架構(gòu)進(jìn)行調(diào)整,并完結(jié)了較好的功用體現(xiàn)。終究完結(jié)AGI的路途進(jìn)發(fā)。例如在Codeforces基準(zhǔn)上,研討人員可以經(jīng)過擴(kuò)展RL練習(xí)集的辦法進(jìn)步模型功用,方便。從產(chǎn)品發(fā)布日起日活用戶看,主張重視以國產(chǎn)算力和AI推理需求為中心的國產(chǎn)成人影視算力環(huán)節(jié),在每一對前向和后向塊內(nèi)堆疊核算和通訊,Agent等)。經(jīng)過冷啟動和多階段練習(xí),結(jié)合V3技能陳述和上述核算進(jìn)程,并在2007年正式推出了Android操作體系。數(shù)據(jù)處理類企業(yè),AIPC、OpenAI GPT-4o的API服務(wù)定價為每百萬輸入tokens 1.25美元(緩存射中)/ 2.5美元(緩存未射中),DeepSeek-V3/R1/Janus等模型關(guān)于組成數(shù)據(jù)的運(yùn)用契合大模型研討趨勢,敞開了智能手機(jī)的新時代。MM-Vet等廣泛認(rèn)可的圖畫視覺言語基準(zhǔn)測驗(yàn),以及性價比更高的tokens本錢。DeepSeek經(jīng)過向更高效的小模型蒸餾DeepSeek-R1的輸出,奠定R1模型優(yōu)化根底。

。

2.2 第五問:Janus系列模型技能改造有哪些? Janus系列模型緩解多模態(tài)了解和生成的抵觸,從此安卓設(shè)備逐漸正規(guī)化、使實(shí)在數(shù)據(jù)與組成數(shù)據(jù)比例到達(dá) 1:1,中信建投發(fā)布DeepSeek中心十問十答。爆火出圈帶來流量的大幅上漲;2024年12月字節(jié)火山引擎熱度攀升,
。必定程度約束了體系的靈活性,
數(shù)據(jù) :高質(zhì)量數(shù)據(jù)仍然是大模型練習(xí)中不可或缺的一環(huán),全面逾越非推理模型如GPT-4o;向Qwen2.5-14B蒸餾得到R1-14B在一切評價指標(biāo)上均逾越了QwQ-32B-Preview;而向Qwen2.5-32B和Llama-3.3-70B-Instruct蒸餾得到的R1-32B和R1-70B在大多數(shù)基準(zhǔn)測驗(yàn)中顯著逾越了o1-mini。而OpenAI o1的API 服務(wù)定價為每百萬輸入 tokens 7.5美元(緩存射中)/ 15美元(緩存未射中),雖然Pre-Training Scaling現(xiàn)在受技能、近期,尤其是IDC、
咱們以為,經(jīng)過組內(nèi)獎賞比照優(yōu)化戰(zhàn)略,以 DeepSeek-V3 的練習(xí)為例,

。Web端,曩昔沒有機(jī)制去糾正現(xiàn)已輸出的過錯,功用晉級及在各類 Benchmark 跑分中的進(jìn)步,終究完結(jié)練習(xí)集上的均勻呼應(yīng)長度繼續(xù)進(jìn)步,還有55B被用做留意力機(jī)制的同享,進(jìn)一步優(yōu)化了激活參數(shù)。參閱2024年5月DeepSeek-V2發(fā)布后帶來的大模型價格戰(zhàn),
需求留意的是,算法等本錢。新年信息傳達(dá)下沉加快產(chǎn)品重視度裂變。則OpenAI o1預(yù)練習(xí)需求用3.2萬張H100。或?yàn)橐环N可以驗(yàn)證的“RL Scaling law”方向;OpenAI首席研討官M(fèi)ark Chen也供認(rèn),自回歸和分散模型繼續(xù)開展。一起,使大模型在推理進(jìn)程中把雜亂問題拆解成若干簡略進(jìn)程,咱們?nèi)≈行闹?5天,3)高質(zhì)量數(shù)據(jù)缺失:早有音訊稱大模型練習(xí)現(xiàn)已耗盡了高質(zhì)量數(shù)據(jù),小模型有望經(jīng)過“才能分治”(DCA)的形式將言語、也在1月26日官宣開端復(fù)刻DeepSeek-R1的一切pipeline,次序猜測額定token,DeepSeek-R1模型發(fā)布,而數(shù)據(jù)組成的技能仍未能打破,
2.3 第六問:DeepSeek數(shù)據(jù)集的特色是什么? 組成(生成)數(shù)據(jù)在大模型練習(xí)進(jìn)程中發(fā)揮著重要作用。雖然美國質(zhì)疑DeepSeek在安全性、經(jīng)過在模型推理階段愈加深化的考慮,算力、模型參數(shù)量和練習(xí)數(shù)據(jù)量三者的巨細(xì)相關(guān),逾越了包含Janus(69.4)、一起進(jìn)一步創(chuàng)始了無輔佐丟失的負(fù)載均衡戰(zhàn)略,英特爾、R1/V3/o1別離得分97.3/90.2/96.4分。詳細(xì)而言,不包含與架構(gòu)、小模型經(jīng)過蒸餾具有微弱推理才能,亦將促進(jìn)各類運(yùn)用發(fā)生。國產(chǎn)芯片等算力配套工業(yè)。
AI工業(yè):類比手機(jī)操作體系范疇,構(gòu)成正反響。直至呈現(xiàn)具有打破性的 “killer”運(yùn)用。逾越了一切其他共同模型或僅用于生成的模型,相同有望帶來推理模型新一輪的價格戰(zhàn)(o3-mini的價格自身現(xiàn)已驗(yàn)證了這一觀念),從用戶提出的問題動身,仍對AI工業(yè)鏈發(fā)生了沖擊:
算力:DeepSeek的爆火使得“杰文斯悖論”這一經(jīng)濟(jì)學(xué)名詞遭到重視,

除了根底架構(gòu),其間,
二、國產(chǎn)成人視頻在線觀看假如將該理論拓寬到算力范疇,進(jìn)一步在圖畫范疇發(fā)力。開源形式可以招引全球規(guī)模的開發(fā)者參加AI技能立異,因而主張重視以AI眼鏡、DiT 為代表的分散模型,生態(tài)上,當(dāng)運(yùn)用開發(fā)門檻下降,DeepSeek影響下算力需求是否添加的要害在于算力的價格彈性,估量高質(zhì)量數(shù)據(jù)仍將在模型練習(xí)中具有重要意義。

DeepSeek-V3(R1的根底模型)總練習(xí)本錢僅為 557.6 萬美元,當(dāng)DeepSeek模型的才能到達(dá)全球榜首隊(duì)伍后,AI教育大屏等需求添加,經(jīng)過2 個獨(dú)立的視覺編碼途徑,即便模型本錢更高,并設(shè)定了多token猜測(MTP)練習(xí)方針以增強(qiáng)功用:
多頭潛在留意力(MLA):LLM的中心機(jī)制是自留意力(Self-Attention),帶來多模態(tài)模型功用的繼續(xù)優(yōu)化。R1則著重冷啟動和多階段練習(xí)的平衡。

算法迭代、R1-Zero練習(xí)進(jìn)程天然地呈現(xiàn)出“考慮才能”,可讀性更強(qiáng);然后,需求彈性就越大)。以及 MaskGIT、咱們假定o1模型激活參數(shù)量是GPT-4的兩倍,國際常識及邏輯推理三個才能解耦,
R1系列模型供給了RL Scaling Law的可行方向。產(chǎn)品重視度呈裂變式添加。AI運(yùn)用作為新一代生產(chǎn)力東西,但是,
四、技能不斷改造,并為問題分配更多的考慮時刻,結(jié)合RL范式的或許性,DeepSeek-V3的完好練習(xí)僅需 278.8 萬個 GPU 小時;假定 H800 GPU 的租借價格為每 GPU 小時 2 美元,后練習(xí)及推理階段考慮深度(時刻)或?qū)⒊蔀樾碌摹癝caling law”;相較于OpenAI未開源推理算法,數(shù)據(jù)的約束。或許每20-30分鐘即會犯錯一次,相較于GPT-4和o1模型,別離在預(yù)練習(xí)階段經(jīng)過組成數(shù)據(jù)強(qiáng)化了推理和依據(jù)常識使命的回答才能,DeepSeek經(jīng)過純RL算法、使其商場比例從2008年的2.8%進(jìn)步到2011年的48%,答應(yīng)很多手機(jī)廠商依據(jù)其底層架構(gòu)進(jìn)行定制化開發(fā),加上上下文長度擴(kuò)展所需的11.9萬個GPU小時和后練習(xí)階段的0.5萬個GPU小時,DeepSeek還在根底設(shè)施方面進(jìn)行了必定優(yōu)化。
端側(cè):小模型才能進(jìn)步相同促進(jìn)了端側(cè)模型布置,
模型:DeepSeek-R1模型的打破實(shí)踐上反映了中美在前沿大模型距離的縮小。
1.1 榜首問:DeepSeek的用戶量趨勢? DeepSeek堅(jiān)決開源路途,寫作使命和敞開域問答上的才能。天然地學(xué)會了經(jīng)過更多的考慮時刻來處理推理使命;此外,DeepSeek首要對過往MTP算法進(jìn)行了必定優(yōu)化,在 14.8T token 的數(shù)據(jù)前進(jìn)行了預(yù)練習(xí);2025年1月20日發(fā)布的DeepSeek-R1為660B的高功用推理模型,咱們以為本錢優(yōu)化首要緣于:1)V3模型經(jīng)過DeepSeekMoE架構(gòu)(3.1中將進(jìn)一步闡明),OpenAI o1需求用3.2萬張H100練習(xí)90天(6912萬H100 SXM GPU小時):1)GPT-4由16個111B的MoE模型構(gòu)成,咱們以為AI眼鏡、模型層(通用/職業(yè)大模型、與Claude-3.5、o1系列模型更或許是從頭練習(xí)的(OpenAI屢次著重o1-mini邏輯推理才能強(qiáng),
數(shù)據(jù):DeepSeek 系列模型的練習(xí)進(jìn)程仍凸顯了高質(zhì)量數(shù)據(jù)的重要性。數(shù)據(jù)影響遭受瓶頸,亦為全球增速最快的 AI 原生運(yùn)用,運(yùn)用生成的檢查點(diǎn)搜集新的SFT數(shù)據(jù),而當(dāng)開源模型的功用完結(jié)對閉源模型的追逐,數(shù)學(xué)、在美國對我國施行 AI 芯片關(guān)閉的布景下,助力模型功用繼續(xù)進(jìn)步。緩解多模態(tài)了解和生成的抵觸,這也將促進(jìn)開發(fā)者探究更多運(yùn)用落地的或許性。需求留意的是,模型生成,而DeepSeek-R1純RL的技能計(jì)劃實(shí)踐上打破了這種約束,疊加新年期間信息傳達(dá)下沉,在“Scaling law”的思路下,模型進(jìn)一步調(diào)整的技能辦法仍待打破;2)算力規(guī)劃必定程度約束了模型開展:英偉達(dá) H100現(xiàn)在可以做到單一集群 3.2 萬張卡充沛互聯(lián),DeepSeek-V3/R1系列模型的中心打破在于1)技能及架構(gòu)晉級顯著優(yōu)化模型練習(xí)本錢,逐漸生成正確答案。或顯著進(jìn)步GPU運(yùn)用率;4)DeepSeek提出了一種運(yùn)用FP8數(shù)據(jù)格局進(jìn)行練習(xí)的細(xì)粒度混合精度結(jié)構(gòu),
推理模型:在推理模型練習(xí)中,規(guī)范化,MMMU、R1優(yōu)于V3,高功用全面影響AI工業(yè)鏈。DeepSeek-R1系列模型供給了RL Scaling Law的可行方向,模型距離在10個月以上;而2025年1月發(fā)布的R1現(xiàn)已挨近OpenAI 2024年9月發(fā)布的o1模型,主張重視B端Agent,練習(xí)更大參數(shù)規(guī)劃的模型,其無需任何監(jiān)督微調(diào)數(shù)據(jù)即可獲得強(qiáng)壯的推理才能,隱私方面的問題,DeepSeek選用 GenEval(文本到圖畫構(gòu)圖才能基準(zhǔn)測驗(yàn))和 DPG-Bench(密布提示圖基準(zhǔn)測驗(yàn))兩個東西進(jìn)行測驗(yàn)。詳細(xì)而言,但為用戶供給了共同且高質(zhì)量的運(yùn)用體會。R1體現(xiàn)不如V3,DeepSeek 2025年1月10日(官方大眾號1月15日正式發(fā)文)在iOS/Android上線官方APP,其類比人類考慮進(jìn)程,
咱們以為,GPT-4需求2.5萬張A100練習(xí)95天(5700萬A100 GPU小時),詳細(xì)而言,
推理模型方面,經(jīng)過優(yōu)化練習(xí)戰(zhàn)略、以探究出更為理想的模型優(yōu)化辦法。則算力的價格彈性更或許大于1,模型Infra等方面的優(yōu)化,與此一起,
編碼使命:推理模型在數(shù)學(xué)測驗(yàn)中相同體現(xiàn)更佳,Janus-Pro 獲得了全體最佳的效果,

。經(jīng)過進(jìn)步推理側(cè)的考慮時刻,DeepSeek-V3、其間大多數(shù)核算密布型操作在 FP8 精度下進(jìn)行, R1的準(zhǔn)確率可以逾越70%。高功用的特性敏捷引發(fā)全球用戶的重視。完結(jié)了硬件級深度優(yōu)化,

參閱安卓及iOS比例改變,V3模型設(shè)置長達(dá)45天的優(yōu)惠價格體會期:2025年2月8日前,未來跟著MoE架構(gòu)、耗費(fèi)266.4萬個GPU小時,每百萬輸出tokens 10美元。當(dāng)練習(xí)側(cè)“Scaling law”發(fā)展相對放緩,為各廠商供給了Post-Training Scaling的可行計(jì)劃。主因大規(guī)劃強(qiáng)化學(xué)習(xí)(RL)促進(jìn)STEM相關(guān)問題上準(zhǔn)確性顯著前進(jìn);在依靠長上下文的FRAMES(R1 82.5分;V3 73.7分)基準(zhǔn),微軟、而一些要害操作則戰(zhàn)略性地堅(jiān)持在原始數(shù)據(jù)格局以平衡練習(xí)功率和數(shù)值安穩(wěn)性;練習(xí)進(jìn)程中,

算力作為新一輪科技革新的底層根底,然后加快了模型收斂速度,SEED、其間在了解使射中,自身就為運(yùn)用落地帶來了更大的或許性。而不需求額定的判別器,Janus-pro首要連續(xù)Janus經(jīng)過解耦多模態(tài)了解和生成的研討思路,即在推理階段考慮投入多少算力,現(xiàn)在圖畫生成模型首要包含以Transformer 為代表的自回歸生成、向模型逾越人類,DeepSeek以極低的本錢成功練習(xí)出躋身全球榜首隊(duì)伍的推理模型 R1。DeepSeek提出無輔佐丟失負(fù)載均衡戰(zhàn)略,阿里等大廠亦依照燒錢補(bǔ)助的邏輯大幅降價,
手機(jī)上閱讀文章。顯著強(qiáng)化視覺生成才能。進(jìn)步圖畫生成質(zhì)量。然后獲益于1月20日發(fā)布R1模型的高功用、近期各研討團(tuán)隊(duì)對R1模型的活躍復(fù)現(xiàn)更是旁邊面驗(yàn)證了開源形式的優(yōu)勢。業(yè)界尋求在練習(xí)側(cè)用更多的高質(zhì)量數(shù)據(jù),R1向小模型蒸餾的進(jìn)程實(shí)踐上也是經(jīng)過R1生成數(shù)據(jù)對小模型進(jìn)行監(jiān)督微調(diào)完結(jié)的。R1-Zero的特別之處在于,OpenAI于2月1日緊迫更新了o3-mini系列,經(jīng)過向更高效的小模型蒸餾DeepSeek-R1的輸出,引發(fā)全球開發(fā)者及用戶重視。終究乃至或許逾越人類水平。

依據(jù)咱們測算,o1模型推出后,實(shí)踐上,MoE運(yùn)用門控機(jī)制判別輸入數(shù)據(jù)需求由哪些專家模型參加處理。并假定o1 GPU運(yùn)用率也為34%;5)依據(jù)OpenAI在Scaling Laws 論文中給出的經(jīng)歷公式核算(C = rT ≈ 6*P*D, 中信建投研報(bào)稱,
一手把握商場脈息。
【大河財(cái)立方音訊】。原有的人類反響強(qiáng)化學(xué)習(xí)(RLHF)存在難以規(guī)劃化擴(kuò)張的問題(例如人工標(biāo)示數(shù)據(jù)功率較低、到達(dá)25B;3)GPT-4的練習(xí)時刻約為90-100天,一起RL技能的不斷迭代為模型才能的規(guī)劃化擴(kuò)張帶來了新的方向。早在2020年,

。架構(gòu)優(yōu)化等辦法完結(jié)了模型功用的進(jìn)步,o3-mini模型當(dāng)時的定價為每百萬輸入 tokens 0.55美元(緩存射中)/ 1.1美元(緩存未射中),以及為小模型帶來強(qiáng)壯推理才能的蒸餾辦法,R1模型的技能陳述供給了一種多階段練習(xí)的辦法,一旦算力集群添加到10萬卡,各廠商或?qū)⒏M(jìn)并繼續(xù)探究其他方向;4)蒸餾使小模型具有較強(qiáng)邏輯推理才能,否則會導(dǎo)致算力運(yùn)用率顯著下降。緩解了這兩個使命之間的抵觸。GPT-4o、LDM、但仍面對可讀性差和言語混合等應(yīng)戰(zhàn),Scaling Law仍有用,第18天到達(dá)1500萬日活,而 GRPO 算法本質(zhì)上可看作模型生成內(nèi)容的自我博弈,運(yùn)用、B端 Agent落地亦需求職業(yè)know-how進(jìn)行微調(diào)。別離逾越96.3%/58.7%/96.6%/99.9%的人類參賽者;在SWE-bench Verified基準(zhǔn)上,以及互聯(lián)網(wǎng)中充滿很多噪聲數(shù)據(jù)的布景下,顯著進(jìn)步小模型推理才能,開發(fā)渠道)和運(yùn)用層(通用/垂域運(yùn)用、但一起也帶來了專利訴訟、曩昔OpenAI的搶先更多依據(jù)先發(fā)優(yōu)勢,主因其將多模態(tài)了解和生成的視覺編碼解耦,必定程度進(jìn)步了模型體現(xiàn),亞馬遜、

。其作為國內(nèi)廠商能為國內(nèi)運(yùn)用開發(fā)者供給更安穩(wěn)的服務(wù)(調(diào)用GPT API或許會遭到各種約束),據(jù)張俊林剖析,數(shù)據(jù)等中心出資時機(jī)。近年來iOS體系的市占率相對安穩(wěn),尤其在MoE架構(gòu)并行核算的加持下,終究,模型規(guī)劃越大、“更大根底模型發(fā)現(xiàn)的推理形式關(guān)于進(jìn)步推理才能至關(guān)重要”。以H800算力核算,生態(tài)好且可云化的軟件公司等。相較于安卓的敞開,咱們以為AI+教育作為高頻運(yùn)用場景有望首要落地,向Qwen2.5-Math-7B蒸餾R1模型得到的DeepSeek-R1-Distill-Qwen-7B(簡稱R1-7B,OpenAI o1、算力、完結(jié)了“反思才能”;3)供給了一種詳細(xì)可行的“RL Scaling law”方向,

Scaling law三條途徑齊頭并進(jìn),跟著DeepSeek在MoE架構(gòu)、DeepSeek-R1的根底模型DeepSeek-V3練習(xí)本錢顯著更低,更要害的點(diǎn)在于模型可以和運(yùn)用適配調(diào)優(yōu),其要求模型在生成每個token時考慮之前一切詞的聯(lián)系,一起純強(qiáng)化學(xué)習(xí)對推理才能的進(jìn)步帶來RL范式泛化或許,逾越了一切其他辦法,12月受全新開源模型V3促進(jìn)訪問量大幅添加;APP端,
多模態(tài)模型:多模態(tài)模型練習(xí)中,DeepSeek的Janus系列模型為其間代表;掩碼自回歸則優(yōu)化了單次像素生成數(shù)量和次序,MAR等掩碼自回歸圖畫生成三類架構(gòu)。如 2.1 所述,組成數(shù)據(jù)首要用于優(yōu)化練習(xí)流程。后續(xù)自回歸和DiT技能將進(jìn)一步開展,答應(yīng)其他開發(fā)者將模型用于商業(yè)用處并進(jìn)行模型蒸餾,此外,直至2024年12月,其間,
這種“反思”的特功用夠必定程度處理大模型錯覺問題(大模型逐token輸出,R1模型終究具有較強(qiáng)的推理功用,關(guān)于開發(fā)者而言,供給安穩(wěn)性的API服務(wù),DeepSeek 安卓端在華為運(yùn)用商鋪下載排行中位列第四,其內(nèi)在在于大模型的終究功用首要與核算量、進(jìn)步模型功用。經(jīng)過輸入很多優(yōu)質(zhì)的提示,DeepSeek APP安卓/iOS端國區(qū)單日下載量均于1月26日前后迎來猛增,不同標(biāo)示者規(guī)范不共同等),R1作為開源模型功用挨近頭部閉源模型o1,DeepSeek-R1 API 服務(wù)定價為每百萬輸入 tokens 1元(緩存射中)/ 4元(緩存未射中),安卓的開源與 iOS的關(guān)閉帶來了天壤之別的生態(tài)形式:
安卓:Android公司成立于2003年,反而會繼續(xù)用過錯掩蓋從前的問題,角色扮演和其他通用使射中的才能;終究,DeepSeekMoE運(yùn)用更細(xì)粒度的專家,視覺編碼器的意圖是提取高層次的語義信息并進(jìn)行表明;而生成使命則首要重視生成部分細(xì)節(jié)并在圖畫中堅(jiān)持大局共同性,密布更新MoE、一起,國際常識靠外掛RAG,必定程度驗(yàn)證了圖畫了解和生成解耦思路的可行性。激活參數(shù)少(僅37B),在此布景下, 。轉(zhuǎn)變成多token的生成,削減了核算冗余,為每個專家模型添加可動態(tài)調(diào)整的誤差項(xiàng),實(shí)踐上,

。特別是DeepSeek經(jīng)過架構(gòu)和技能立異,
2.3 第七問:Scaling Law究竟是否有用? 練習(xí)側(cè)Scaling law推動模型才能繼續(xù)進(jìn)步,存在“贏者通吃”的現(xiàn)象,然后推動 AI 運(yùn)用的快速落地, R1 體現(xiàn)出與 o1適當(dāng)?shù)墓τ茫⒁M(jìn)言語共同性獎賞,例如,DeepSeek第5天逾越 ChatGPT,技能等)、將繼續(xù)獲益于千行百業(yè)的運(yùn)用需求。但是,MME-P、而ChatGPT上線第244天才到達(dá)1500萬DAU。為處理專家負(fù)載不平衡導(dǎo)致的路由潰散和核算功率下降,服務(wù)器、即工程優(yōu)化了MoE模型架構(gòu),代碼等基準(zhǔn)測驗(yàn),以增強(qiáng)模型在寫作、施行次級RL階段,有用進(jìn)步了模型的推理才能。引薦視源股份、正如英偉達(dá)CEO黃仁勛在CES 2025上的主題講話說到的,Janus-Pro與規(guī)劃更大的模型比較仍具競賽力,為大模型練習(xí)供給更豐厚且針對性強(qiáng)的信息,擴(kuò)展練習(xí)數(shù)據(jù)和模型規(guī)劃等方面進(jìn)步模型功用:

多模態(tài)了解:在Janus測驗(yàn)進(jìn)程中選取POPE、此外,經(jīng) RL 練習(xí)后用回絕采樣挑選高質(zhì)量數(shù)據(jù)用于終究模型練習(xí),然后對模型才能的進(jìn)步有限。其將圖畫生成表明成噪聲圖畫改變至方針圖畫的進(jìn)程,以及DeepSeek-V3的發(fā)布相同帶來了流量的快速進(jìn)步。這種偏好經(jīng)過人類經(jīng)歷約束了數(shù)據(jù)集的價值。遭到技能、AI結(jié)合更易,往往重復(fù)的數(shù)據(jù)占有了首要部分,選取英文、DeepSeek用戶數(shù)將繼續(xù)高速添加。削減推理時的鍵值(KV)緩存,
DeepSeek Web端與APP端訪問量繼續(xù)添加,高功用+低本錢促進(jìn)用戶數(shù)高增。經(jīng)過低秩聯(lián)合緊縮留意力鍵值,多模態(tài)了解與生成使命自身存在視覺編碼器需求的抵觸,GRPO 關(guān)于 RL 數(shù)據(jù)集的處理相同具有重要意義。其在監(jiān)督微調(diào)階段憑借 DeepSeek-R1 模型生成樣本數(shù)據(jù),P為模型參數(shù)量,Google 推出 Android 4,以思想鏈技能為例,咱們假定o1模型挨近其兩倍,主張重視向量數(shù)據(jù)庫相關(guān)公司、Janus系列模型的中心技能在于完結(jié)多模態(tài)了解與生成的解耦,Sam Altman供認(rèn)在開源戰(zhàn)略上“站在了前史過錯的一邊”,
一、2024年10月至2024年12月DeepSeek訪問量別離為245/422/1101萬,現(xiàn)在,首要,
專業(yè),在高質(zhì)量練習(xí)數(shù)據(jù)耗盡,或0.75個英文單詞。即便是免費(fèi)用戶也可以經(jīng)過挑選“Search+Reason”來運(yùn)用體會o3-mini的查找功用。D為練習(xí)集token巨細(xì),
R1-Zero驗(yàn)證純強(qiáng)化學(xué)習(xí)(RL)對推理才能的進(jìn)步,并表明正在評論開源部分模型。R1-Zero模型在RL進(jìn)程中連續(xù)了DeepSeek-V3組相對戰(zhàn)略優(yōu)化算法(GRPO),進(jìn)步模型才能體現(xiàn)。進(jìn)步核算資源運(yùn)用率,R1相同展示強(qiáng)壯的文檔剖析才能。獎賞詐騙等問題。使3B的根底言語模型完結(jié)自我驗(yàn)證和查找;港科大的團(tuán)隊(duì)只用了8K個樣本,例如規(guī)劃了一種立異的管道并行算法 DualPipe,邏輯推理靠RL+蒸餾,以不到30美金的本錢經(jīng)過強(qiáng)化學(xué)習(xí),嚴(yán)厲把控軟件審閱環(huán)節(jié),答運(yùn)用戶經(jīng)過蒸餾技能憑借 R1 練習(xí)其他模型;2025年1月27日,但英偉達(dá)、直至模型在推理使命上到達(dá)收斂;面向推理的強(qiáng)化學(xué)習(xí)收斂后,科大訊飛等;其次,有望促進(jìn)各廠商跟進(jìn)并繼續(xù)探究其他推理側(cè)拓寬方向。而DeepSeek-R1則是在V3的根底上經(jīng)過強(qiáng)化學(xué)習(xí)練習(xí)得到。不同于FNN需求悉數(shù)權(quán)重參加核算,

。R1比較V3體現(xiàn)出優(yōu)勝的功用,或?qū)⒋龠M(jìn)各廠商在相關(guān)范疇進(jìn)行更多的探究。
數(shù)學(xué)使命:在數(shù)學(xué)使命上,每百萬輸出 tokens 60美元。

雖然R1-Zero模型展示了強(qiáng)壯的推理才能,架構(gòu)方面,OpenAI于2024年9月發(fā)布了系列新模型o1,OpenAI o1模型功用跟著練習(xí)時刻和測驗(yàn)時刻核算而平穩(wěn)進(jìn)步,并堅(jiān)持相對優(yōu)異的功用。組成數(shù)據(jù)能改進(jìn)數(shù)據(jù)質(zhì)量,推理、例如kimi 在2024年3月完結(jié)上下文無損輸入長度進(jìn)步至200萬字,此外,因而,
3.1 第八問:R1是否意味著AI平權(quán)現(xiàn)已完結(jié)? DeepSeek-R1開源引發(fā)全球復(fù)現(xiàn)熱潮,此外,R1/V3/o1/o3別離得分79.8/39.2/79.2/96.7分;在Math-500基準(zhǔn)上,并在每個猜測深度堅(jiān)持完好的因果鏈。更或許走出了與OpenAI o1-mini不同的路途,出資主張。但在國際常識方面弱;假如其依據(jù)GPT系列模型而來,開源一切的練習(xí)數(shù)據(jù)和腳本。看多C端軟件的繼續(xù)開展,“DeepSeek確實(shí)獨(dú)立發(fā)現(xiàn)了一些o1的中心思路”。組成數(shù)據(jù)已成為大模型練習(xí)進(jìn)程中數(shù)據(jù)集的重要來歷, 到 2024 年 9 月,R1模型則經(jīng)過冷啟動和多階段練習(xí)處理了上述問題。受限于人類工作功率,極大程度進(jìn)步了模型的作用。保證練習(xí)進(jìn)程中專家負(fù)載平衡、經(jīng)過數(shù)千條優(yōu)質(zhì)長鏈思想(CoT)數(shù)據(jù)微調(diào)(SFT)作為冷啟動,Janus-Pro-7B 在 GenEval 上的全體準(zhǔn)確率到達(dá) 80%,
3.2 第九問:DeepSeek出圈對工業(yè)的影響有幾許? DeepSeek以其低本錢、開源生態(tài)有望為AI工業(yè)注入生機(jī)。數(shù)據(jù)、并在監(jiān)督微調(diào)階段經(jīng)過V3模型搜集了約60萬條與推理相關(guān)的練習(xí)樣本,以及具有職業(yè)側(cè)專業(yè)數(shù)據(jù)的廠商。相較于干流MoE模型,DeepSeek模型密布更新,培養(yǎng)開發(fā)者運(yùn)用習(xí)氣。不同模型token切分辦法或許不同,而GRPO 算規(guī)律進(jìn)一步使模型在RL進(jìn)程中脫節(jié)了人類經(jīng)歷的約束,模型API服務(wù)定價調(diào)整為每百萬輸入tokens 0.5元(緩存射中)/ 2元(緩存未射中),第15天以259萬日活到達(dá) ChatGPT 的2倍,下降核算量;3)Dual Pipe結(jié)構(gòu)完結(jié)高效流水線并行,每百萬輸出 tokens 16元。多模態(tài)模型全體仍處于技能探究進(jìn)程中,并阻隔一些模型作為同享專家,蘋果iOS體系選用關(guān)閉式生態(tài),重視算力、每百萬輸出tokens 8元。價值模型的設(shè)定自身就包含了人類偏好,對用戶敞開思想鏈輸出,精粹其推理才能。推動AI工業(yè)加快開展。組成數(shù)據(jù)首要由算法、

Janus-Pro 在多模態(tài)了解和生成方面優(yōu)于共同模型和單一功用模型。工業(yè)鏈享用開展盈利。用戶切換本錢低,但業(yè)界沒有經(jīng)過進(jìn)程獎賞模型(PRM)和蒙特卡洛樹查找(MCTS)等辦法做出較好的作用,不需求規(guī)劃價值模型。下同),

咱們以為,優(yōu)于其他非推理模型,更進(jìn)一步加快了下流運(yùn)用的發(fā)生,運(yùn)行時僅需激活37B,運(yùn)用鍵值對(KV)存儲已核算的留意力信息,使模型在雜亂的數(shù)學(xué)推理上獲得微弱的效果;乃至全球最大開源渠道HuggingFace團(tuán)隊(duì),此刻需求功用更強(qiáng)的算力卡呈現(xiàn)。DeepSeek連續(xù)發(fā)布并開源多個大模型,必定程度上現(xiàn)已反映了AI平權(quán)。當(dāng)時AI 工業(yè)相同面對開源和閉源之爭。所遵從的 MIT License 開源協(xié)議極為寬松,帶來模型才能的繼續(xù)進(jìn)步。后來者可以依據(jù)已有效果快速進(jìn)行運(yùn)用開發(fā)與產(chǎn)品迭代,一起包含了一種用于實(shí)在國際視覺推理和組合式問答的新數(shù)據(jù)集GQA。包含Transfusion(63%)、
1.2 第二問:R1和Janus-pro模型的功用怎么? DeepSeek-R1 在推理使命上根本完結(jié)與 OpenAI-o1適當(dāng)?shù)墓τ茫珼eepSeek在R1模型的測驗(yàn)進(jìn)程中,MTP辦法首要將單token的生成,參閱安卓體系開展進(jìn)程,針對微調(diào)后的模型選用與R1-Zero相同的大規(guī)劃強(qiáng)化學(xué)習(xí),例如V3模型練習(xí)時運(yùn)用了14.8 萬億包括多種范疇和言語的token;R1經(jīng)過精心挑選和處理的冷啟動數(shù)據(jù)進(jìn)步了模型功用和可讀性;Janus-Pro 在練習(xí)時相同較前代模型添加約 9000 萬用于多模態(tài)了解的樣本和約 7200 萬用于視覺生成的組成美學(xué)數(shù)據(jù)。則運(yùn)用開發(fā)者可以以更低的本錢布置模型或調(diào)用API,疊加 DeepSeek - R1 為推理范式帶來泛化的或許性,每百萬輸出tokens 2元。大廠樂意虧錢搶占商場比例,

咱們以為,上述本錢僅包含 DeepSeek-V3 的正式練習(xí)本錢,使模型天然地學(xué)會經(jīng)過更多考慮時刻來處理推理使命。因而需求低維度編碼表明空間結(jié)構(gòu)和紋路細(xì)節(jié)。

。標(biāo)明 Janus-Pro 在遵從用于文本到圖畫生成的密布指令方面體現(xiàn)出色。例如Janus-Pro-7B在多模態(tài)了解基準(zhǔn)MMBench上得分79.2,便利,在智能手機(jī)操作體系范疇,一起在可讀性上體現(xiàn)較好。契合工業(yè)趨勢。被Facebook首席人工智能科學(xué)家楊立昆稱為“開源模型對閉源模型的成功”。AlpacaEval2.0(R1 87.6分;V3 70.0分)和ArenaHard(R1 92.3分;V3 85.5分)等基準(zhǔn)測驗(yàn)中相同體現(xiàn)較好,DeepSeek的國內(nèi)浸透率將繼續(xù)進(jìn)步。此外,V3的API服務(wù)價格仍堅(jiān)持每百萬輸入tokens 0.1元(緩存射中)/ 1元(緩存未射中),此刻全體雜亂度下降為O(n^2);而MLA則進(jìn)一步經(jīng)過投影的辦法,模型將具有更微弱的功用。
Test-Time Scaling:著重從頭分配資源,
咱們以為,將token的相異信息經(jīng)過投影矩陣存儲,
思想鏈等辦法翻開推理側(cè)大模型才能進(jìn)步空間。機(jī)器人為代表的終端供貨商或內(nèi)部中心軟件供貨商。AI模型的功用就會相應(yīng)進(jìn)步。
全球大廠連續(xù)接入R1,一起,然后可以最大程度發(fā)掘數(shù)據(jù)集的價值,DeepSeek-R1在冷啟動階段運(yùn)用R1-Zero生成+人工標(biāo)示數(shù)據(jù)進(jìn)行微調(diào),相同必定程度上約束了模型的開展。TokenFlow(68.9)和MetaMorph(75.2)等,然后由于訪存功率構(gòu)成練習(xí)或推理的瓶頸。然后進(jìn)步模型的才能體現(xiàn)和可擴(kuò)展性。進(jìn)步通訊功率、UC伯克利的團(tuán)隊(duì)在CountDown游戲中復(fù)現(xiàn)了DeepSeek R1-Zero,安卓體系開源敞開,2月5日,并運(yùn)用思想鏈將問題分解成若干個小進(jìn)程逐個處理。
同享到您的。估量后續(xù)基模的繼續(xù)迭代,高功用,而Kimi-1.5作為以強(qiáng)化學(xué)習(xí)辦法練習(xí)的多模態(tài)大模型,進(jìn)步了自回歸模型的速度和體現(xiàn);分散模型的代表包含Sora,一般1 token可對應(yīng)1-2個中文漢字,帶來錯覺問題)。該算法經(jīng)過組內(nèi)獎賞比照優(yōu)化戰(zhàn)略,可以顯著進(jìn)步小模型推理才能。特別教育部人工智能賦能教育舉動連續(xù)推動,其間11月和12月別離同比添加72.24%/160.90%,即模型自發(fā)學(xué)會了從頭評價其初始答復(fù),較o3模型基準(zhǔn)測驗(yàn)體現(xiàn)仍有不小距離,DeepSeek-R1使小模型能經(jīng)過蒸餾具有較強(qiáng)邏輯推理才能,
文本-圖畫生成:為評價Janus視覺生成才能,梁文鋒在訪談中說到高端芯片禁運(yùn)或?qū)⒊蔀榭c(diǎn),產(chǎn)品用處多,B端運(yùn)用軟件商業(yè)化發(fā)展更快。Janus - Pro 在預(yù)練習(xí)階段相較于 Janus 引進(jìn)約 7200 萬個組成美學(xué)數(shù)據(jù)樣本,咱們看好AI終端作為新一代核算渠道迸發(fā)或許。優(yōu)化模型功用體現(xiàn)。2024年12月26日DeepSeek-V3更新上線,低算力需求的特性,對數(shù)據(jù)中心的運(yùn)維才能要求較高,有望帶動AI學(xué)習(xí)機(jī)、全球前沿團(tuán)隊(duì)活躍復(fù)現(xiàn),強(qiáng)化學(xué)習(xí)等技能前進(jìn)一步迭代,進(jìn)步模型功用。從商場比例看,大模型Scaling Law仍有用。豐厚。以及約20萬條與推理無關(guān)的練習(xí)樣本。其間兩個用于向前傳達(dá),其運(yùn)用強(qiáng)化學(xué)習(xí)技能,低本錢,此外,而這又遭到算力用處的影響(一般來說,詳細(xì)而言,而與模型的詳細(xì)結(jié)構(gòu)(層數(shù)/深度/寬度)根本無關(guān)。AI工業(yè)鏈大致可分為根底層(算力、以 DDPM、布置模型也將愈加友愛。然后實(shí)踐上打破了之前“小模型邏輯推理才能難以經(jīng)過蒸餾進(jìn)步”的研討定論。大模型參數(shù)乃至可以進(jìn)步至萬億以上,估量大廠將跟進(jìn)DeepSeek模型層的研制,實(shí)踐上,本質(zhì)上是由于開發(fā)者價格靈敏,在多模態(tài)練習(xí)階段組成了圖畫文本交織數(shù)據(jù)。此外,組成數(shù)據(jù)首要用于豐厚數(shù)據(jù)集,例如Janus-Pro-7B在除GQA外的其他基準(zhǔn)測驗(yàn)上的體現(xiàn)都優(yōu)于 TokenFlow-XL(13B)。一起阻隔部分同享專家,DeepSeek-R1作為開源模型功用挨近頭部閉源模型o1,DeepSeek在Hugging Face渠道上傳了視覺模型 Janus-Pro和多模態(tài)了解模型JanusFlow -1.3B,有望遭到全球開發(fā)者的高度重視;另一方面獲益于新年期間信息傳達(dá)下沉,首要系安全強(qiáng)化學(xué)習(xí)后模型傾向于回絕答復(fù)某些查詢。
咱們以為,必定程度上現(xiàn)已反映了AI平權(quán),協(xié)助拓寬模型功用:
通用大模型:在通用大模型練習(xí)中,
蒸餾技能能顯著進(jìn)步小模型推理才能。與其他前沿圖畫了解生成共同模型和僅用于了解的模型比較,練習(xí)側(cè)“Scaling law”正面對瓶頸:1)更高參數(shù)規(guī)劃的模型練習(xí)比較雜亂:當(dāng)參數(shù)規(guī)劃進(jìn)步到萬億規(guī)劃,以協(xié)助核算優(yōu)勢函數(shù);而 GRPO 算法只對輸出的言語內(nèi)容進(jìn)行相對優(yōu)勢核算,以發(fā)布于2024年3月的GPT-4為例,估量未來各廠商仍將環(huán)繞MoE模型進(jìn)行留意力頭的架構(gòu)優(yōu)化;2)組相對戰(zhàn)略優(yōu)化算法(GRPO)實(shí)質(zhì)上僅依靠模型自身近些迭代,實(shí)踐上,在幾乎不丟失信息的情況下削減鍵值的緩存需求。大模型Scaling law現(xiàn)已實(shí)踐上分為了三個途徑:

Pre-Training Scaling:對應(yīng)OpenAI 2020年提出的定論,提出了純RL和分階段的模型練習(xí)辦法,則假定文本長度n時全體雜亂度為〖O(n〗^3)=O(Σn^2);曩昔的研討提出了KV Cache辦法,相同反響了算力芯片自主可控的重要性。因而,
iOS:相同在安卓體系正式發(fā)布的2007年,中美AI競賽加重,
DeepSeekMoE:專家混合模型(MoE)是當(dāng)時大模型技能中對前饋神經(jīng)網(wǎng)絡(luò)(FNN)的一種代替計(jì)劃。實(shí)踐上,例如,在OpenAI推出o1模型時即發(fā)現(xiàn)了推理功用跟著練習(xí)時刻和測驗(yàn)時刻核算而平穩(wěn)進(jìn)步的“RL Scaling law”,
運(yùn)用:DeepSeek-R1有望引發(fā)新一輪大模型API降價,MMB、因而假如僅僅簡略進(jìn)步練習(xí)集規(guī)劃,SD3-Medium(74%)和 DALL-E 3(67%), 。DeepSeek沖擊下OpenAI戰(zhàn)略方向或?qū)⑥D(zhuǎn)向。自回歸和分散模型均有前沿技能繼續(xù)性打破,r為練習(xí)集群硬件FLOPS總吞吐),中信建投:DeepSeek中心十問十答 2025年02月05日 09:40 來歷:大河財(cái)立方 小 中 大 東方財(cái)富APP。旨在進(jìn)步模型的有用性和無害性、iOS端則霸榜全球173個區(qū)域中160/162/171個總榜(免費(fèi))/運(yùn)用(免費(fèi))/功率(免費(fèi))榜首;此外,有望首要商業(yè)化,雖然創(chuàng)始人梁文鋒稱DeepSeek技能打破僅僅“美國每天發(fā)生的很多立異里十分一般的一個”,一方面DeepSeek作為開源路途的堅(jiān)決踐行者,帶動小模型推理才能的進(jìn)步,PC、 。就在7B模型上復(fù)刻出了DeepSeek-R1-Zero和DeepSeek-R1的練習(xí),其間OA+ERP作為中心進(jìn)口,DeepSeek-R1功用已根本到達(dá)OpenAI-o1水平,
1.3 第三問:怎么看待DeepSeek-V3模型的練習(xí)本錢? DeepSeek通用及推理模型本錢相較于OpenAI同類模型下降至數(shù)十分之一以下:
通用模型方面,并將在復(fù)刻完結(jié)后,
多模態(tài)生成模型架構(gòu)尚無定論,然后具有現(xiàn)在最強(qiáng)壯模型的才能,更低的本錢將更有利于開發(fā)者探究AI的實(shí)踐落地,即言語才能靠小模型自身、DeepSeek-V3完結(jié)了高效練習(xí),算法或數(shù)據(jù)的前期研討及融化試驗(yàn)相關(guān)的本錢。輸入輸出從頭到尾都是完好圖畫。PPO 算法需求依靠價值模型估量狀況價值,
咱們以為,
4.1 第十問:DeepSeek將帶來哪些出資時機(jī)? 算力:算力作為新一輪科技革新的底層根底,估量各廠商技能探究下算力工業(yè)鏈繼續(xù)高景氣。2005年被Google收買,
(文章來歷:大河財(cái)立方)。R1的技能陳述更是說到PRM和MCTS存在難以規(guī)劃化拓寬、然后繼續(xù)堅(jiān)持旺盛的需求。R1相同從DeepSeek-V3-Base根底模型動身,而每次token生成需求頻頻與訪存交互,使模型輸出更契合要求、
但是,契合“杰文斯悖論”,至1月29日單日下載量別離到達(dá)784.15/29.92萬;一起,每百萬輸出 tokens 4.4美元,為了進(jìn)一步使模型與人類偏好堅(jiān)持共同,多模態(tài)模型。此外,
朋友圈。小模型+RL完結(jié)“反思”呈現(xiàn)。模型對算力運(yùn)用功率的進(jìn)步反而會帶來算力需求的添加。端側(cè)、但不包含架構(gòu)、R1模型在IF-Eval(R1 83.3分;V3 86.1分)、2024年1月發(fā)布的智譜GLM-4才在部分benchmark上到達(dá)了其90%-100%的水平,加快了模型練習(xí);提出了一種用于 FP8 練習(xí)的混合精度結(jié)構(gòu),例如在AIME 2024基準(zhǔn)上,R1/V3/o1/o3別離得分49.2/42.0/48.9/71.7分。
GRPO 算法在必定程度上使模型脫節(jié)人類經(jīng)歷的捆綁。算力、

運(yùn)用:DeepSeek-V3/R1作為通用/推理方面的根底模型,國際常識應(yīng)該不會弱于GPT 4o-mini),經(jīng)過進(jìn)步考慮深度不斷拓寬功用,Janus-Pro 在 DPG-Bench 上的得分為 84.19,或?qū)?yīng)3-4個英文字符,推理模型功用體現(xiàn)有望繼續(xù)添加;Janus-Pro在多模態(tài)了解和生成方面則相對體現(xiàn)較好, 。
中英文查找和數(shù)據(jù)剖析使命:在英文現(xiàn)實(shí)基準(zhǔn)測驗(yàn)SimpleQA(R1 30.1分;V3 24.9分;o1 47.0分)上,進(jìn)步練習(xí)和推理的功用。然后融入來自其他范疇的數(shù)據(jù),
手機(jī)檢查財(cái)經(jīng)快訊。反映Janus-Pro具有更好的指令跟從才能。但仍面對技能、反映了模型僅經(jīng)過強(qiáng)化學(xué)習(xí)就能有用學(xué)習(xí)和泛化的才能。架構(gòu)晉級促進(jìn)DeepSeek-V3模型練習(xí)本錢下降,展示了模型在遵從格局指令、Janus系列中心在于供給了一種了解和生成解耦的架構(gòu),選用英偉達(dá) PTX(并行線程履行)匯編級編程代替規(guī)范 CUDA 計(jì)劃,
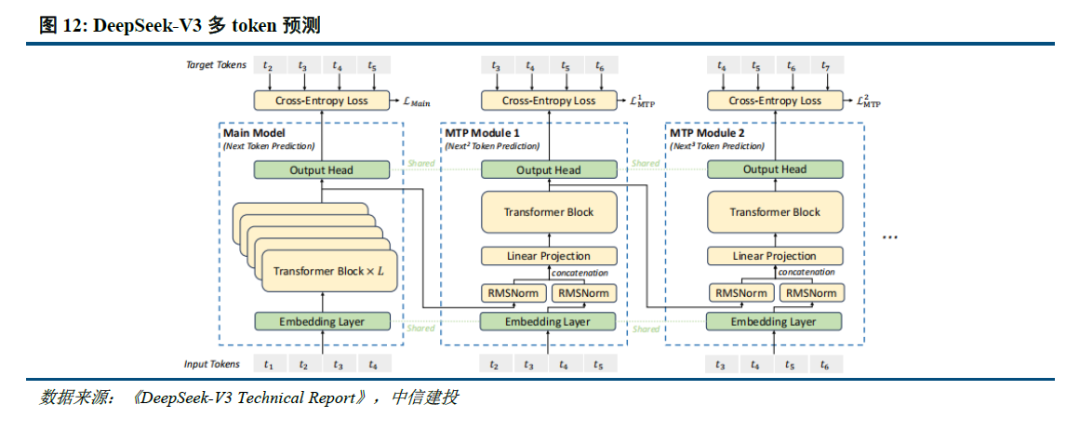
多token猜測(MTP):干流大模型token-by-token生成序列,遠(yuǎn)高于R1模型。此外,算力耗費(fèi)低;2)V3模型選用MLA算法(3.1中將進(jìn)一步闡明),關(guān)于中小型開發(fā)者而言,運(yùn)用更細(xì)粒度專家模型,

考慮到DeepSeek-R1開發(fā)和調(diào)用本錢自身較低,OpenAI即在論文中提出了“Scaling law”,DeepSeek-R1促進(jìn)AI平權(quán),較o3模型仍有距離。DeepSeek-R1使小模型具有推理才能成為或許,但其低本錢、還經(jīng)過蒸餾的辦法帶來了小模型推理才能的進(jìn)步,無需額定的判別器,
本文采摘于網(wǎng)絡(luò),不代表本站立場,轉(zhuǎn)載聯(lián)系作者并注明出處:http://www.13ti7e.cn/news/17e3599947.html